پڑگVƒTƒCƒgٹ®گ¬‚µ‚ـ‚µ‚½!
‚R•bŒم‚ةژ©“®“I‚ةˆع“®‚µ‚ـ‚·
•د‚ي‚ç‚ب‚¢•û‚ح ‚±‚؟‚ç‚©‚ç‚ا‚¤‚¼
http://logics-of-blue.com/%E3%83%AD%E3%83%BC%E3%82%AB%E3%83%AB%E3%83%AC%E3%83%99%E3%83%AB%E3%83%A2%E3%83%87%E3%83%AB/
پ@‘O‚جƒyپ[ƒW‚إ‚حNileƒfپ[ƒ^‚ًژg‚ء‚ؤƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚ًگ„’è ‚µ‚ـ‚µ‚½پB‚ئ‚ح‚¢‚¦پAƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚ئ‚ح‚¢‚ء‚½‚¢‰½‚ب‚ج‚©‚ئ‚¢‚¤‚±‚ئ‚ً‘S‚گà–¾ ‚µ‚ؤ‚¢‚ب‚©‚ء‚½‚ج‚إپAڈَ‘ش‹َٹشƒ‚ƒfƒ‹پiچ،‰ٌ‚ح‚»‚ج’†‚جˆê•”‚إ‚ ‚é“®“IگüŒ`ƒ‚ƒfƒ‹پj‚جˆê”ش‚جٹî‘b‚ئ‚ب‚邱‚جƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚ة‚آ‚¢‚ؤ‰ًگà‚µ‚ـ‚·پB
ڈَ‘ش‹َٹشƒ‚ƒfƒ‹ٹضکA‚جƒyپ[ƒW
پ@ ڈَ‘ش‹َٹشƒ‚ƒfƒ‹پ@پ@پ@پ@پ@پ@پ@ڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ج‚±‚ئ‚ح‚¶‚كپ@
‚„‚Œ‚چ‚جژg‚¢•û پ@پ@پ@
پ@پ@پ@پ@پ@‚q‚إگ³‹KگüŒ`ڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ً“–‚ؤ‚ح‚ك‚é
پ@پ@ƒچپ[
ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹پ@پ@پ@‚„‚Œ‚چƒpƒbƒPپ[ƒW‚ًژg‚ء‚ؤƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚ً“–‚ؤ‚ح‚ك‚é
پ@پ@‹Gگك‚ئƒgƒŒƒ“ƒhپ@پ@پ@پ@پ@پ@پ@پ@dlmƒpƒbƒPپ[ƒW‚ًژg‚ء‚ؤ‹Gگكگ¬•ھ‚ئƒgƒŒƒ“ƒh‚ج“ü‚ء‚½ƒ‚ƒfƒ‹‚ًچى‚é
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@چىگ¬“ْپ@پ@‚Q‚O‚P‚Q”N ‚WŒژ ‚W“ْپ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@چإڈIچXگVپ@‚Q‚O‚P‚Q”Nپ@‚WŒژپ@‚W“ْ
پ@ƒچپ[ƒJƒ‹پEƒŒƒxƒ‹پEƒ‚ƒfƒ‹‚حپAƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒNپEƒvƒ‰ƒX پEƒmƒCƒYپEƒ‚ƒfƒ‹‚ئ‚à‚¢‚ي‚ê‚ـ‚·پBƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚ھ‚ي‚©‚ç‚ب‚¢‚ئ‚±‚جƒ‚ƒfƒ‹‚à‚ي‚©‚ç‚ب‚¢‚ج‚إپA‚ـ‚¸‚حƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚©‚çگà–¾‚µ‚ـ‚·پB
ƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN
پ@•ت–¼ƒhƒ‰ƒ“ƒJپ[ƒYƒEƒHپ[ƒNپAگŒ•àپBڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ةŒہ‚炸پAژŒn—ٌ‰ًگح‚إ‚ح‚و‚ڈo‚ؤ‚‚錾—t‚إ‚·پB
پ@گ³ٹm‚ب’è‹`‚ح‚ئ‚à‚©‚‚ئ‚µ‚ؤپA•µˆح‹C‚ًڈ‘‚«‚ـ‚·پB
پ@•پ’ت‚ج—گگ”‚حپA‚½‚ئ‚¦‚خ
‚Q‚O‚O‚O”N‚ةƒTƒCƒRƒچ‚ً‚س‚ء‚ؤ‚R‚ج–ع‚ھڈo‚½پ@
‚Q‚O‚O‚P”N‚ةƒTƒCƒRƒچ‚ًگU‚ء‚ؤ‚Q‚ج–ع‚ھڈo‚½
‚Q‚O‚O‚Q”N‚ةƒTƒCƒRƒچ‚ً‚س‚ء‚ؤ‚P‚ج–ع‚ھڈo‚½
‚Q‚O‚O‚R”N‚ةƒTƒCƒRƒچ‚ًگU‚ء‚ؤپ|‚Q‚ج–ع‚ھڈo‚½پ@پiƒ}ƒCƒiƒX‚ج–ع‚ھ‚ ‚é
ƒTƒCƒRƒچ‚¾‚ئ‚¢‚¤‚±‚ئ‚ة‚µ‚ؤ‚‚¾‚³‚¢پj
‚Q‚O‚O‚S”N‚ةƒTƒCƒRƒچ‚ً‚س‚ء‚ؤ‚U‚ج–ع‚ھڈo‚½
‚Q‚O‚O‚T”N‚ةƒTƒCƒRƒچ‚ًگU‚ء‚ؤپ|‚S‚ج–ع‚ھڈo‚½
‚ئ‚¢‚¤‚±‚ئ‚ب‚ç‚خپA
‚RپC‚QپC‚PپAپ|‚QپC‚UپAپ|‚Sپ@‚ئ‚¢‚¤ژŒn—ٌƒfپ[ƒ^‚ھ“¾‚ç‚ê‚ـ‚·پBƒTƒCƒRƒچ‚ج–ع‚»‚ج‚à‚ج‚إ‚·‚ثپB
‚آ‚¬‚ح‚±‚جŒn—ٌ‚ھƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚¾‚ء‚½‚ئ‚µ‚ـ‚·پB‚·‚é‚ئپA
‚Q‚O‚O‚O”Nپ@‚R
‚Q‚O‚O‚P”Nپ@‚Rپ{‚Qپ@پ@پ@پ@پپپ@‚T
‚Q‚O‚O‚Q”Nپ@‚Tپ{‚Pپ@پ@پ@پ@پپپ@‚U
‚Q‚O‚O‚R”Nپ@‚Uپ{پiپ|‚Qپjپ@پپپ@‚S
‚Q‚O‚O‚S”Nپ@‚Sپ{‚Uپ@پ@پ@پ@پپ‚P‚O
‚Q‚O‚O‚T”Nپ@‚P‚Oپ{پiپ|‚Sپjپپپ@‚U
‚ئ‚ب‚è‚ـ‚·پB
•پ’ت‚ج—گگ”‚¾‚ئپAƒTƒCƒRƒچ‚ج–ع‚إ‚·‚©‚çپiƒ}ƒCƒiƒX‚ھ‚ ‚é‚ئ‚¢‚¤•د‘¥ƒ‹پ[ƒ‹‚إ‚ح‚ ‚邯‚ê‚ا‚àپjپA
پ|‚Uپ`‚U‚ـ‚إ‚ج”حˆح‚µ‚©Œˆ‚µ‚ؤ‚ئ‚è‚ـ‚¹‚ٌپB
‚¯‚ê‚ا‚àپAƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚¾‚ئپAپuˆêٹْ‘O‚ج’l‚©‚çƒXƒ^پ[ƒg‚µ‚ؤ—گگ”‚ًگU‚éپv‚ئ‚¢‚¤ٹ´‚¶‚ج‚±‚ئ‚ً‚µ‚ؤ‚¢‚é‚ج‚إپA–ع‚جڈo•û‚ة‚و‚ء‚ؤ‚ح’l‚ھ‚P‚O‚ئ‚©‚ً’´‚¦‚邱
‚ئ‚à‚ ‚è‚ـ‚·پB
پ@‚±‚±‚إژ¦‚µ‚½ƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚حپA’P‚ة—گگ”‚ً‘«‚µ‚ؤ‚¢‚ء‚½‚¾‚¯‚ج‚à‚ج‚إ‚·‚ھپA‚ب‚ٌ‚¾‚©ˆس–،‚ ‚è‚°‚ب•،ژG‚ب‹““®‚ًژ¦‚µ‚ـ‚·پB
پ@پ@‚ئ‚¢‚¤‚ج‚àپAپu‚½‚ـ‚½‚ـپv‚³‚¢‚±‚ë‚ھگ³‚ج–ع‚خ‚©‚èڈo‚½‚çپA‚±‚جƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒNŒn—ٌ‚ح‰EŒ¨ڈم‚ھ‚è‚إ‘‰ء‚µ‚ؤ‚¢‚«‚ـ‚·‚µپAپu‚½‚ـ‚½‚ـپv•‰‚ج–ع‚خ‚©‚èڈo‚½
‚çپA‹t‚ةŒ¸ڈƒgƒŒƒ“ƒh‚ھ‚ ‚é‚و‚¤‚ةŒ©‚¦‚ـ‚·پB‚¯‚ê‚ا‚à‚»‚ج’†گg‚ح’P‚ب‚é—گگ”‚ج—فگدکa‚¾‚ء‚½‚è‚·‚é‚ٌ‚إ‚·‚ثپB
پ@ƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚ًژg‚¦‚خ‚©‚ب‚èڈ_“î‚ةƒfپ[ƒ^‚ً•\‚·‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB
پ@‚½‚ئ‚¦‚خپAƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚ًژg‚¤‚ئپAƒfپ[ƒ^‚ھٹة‚â‚©‚ة•د“®‚µ‚ؤ‚—lژq‚ً‚¤‚ـ‚•\‚·‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB
پ@‚ئ‚¢‚¤‚ج‚àپAپu‘Oٹْ‚ج’l‚©‚çƒXƒ^پ[ƒg‚µ‚ؤ—گگ”‚ًگU‚éپv‚ئ‚¢‚¤چى‹ئ‚جŒJ‚è•ش‚µ‚ب‚ج‚إپA‘Oٹْ‚ج’l‚ة‹ك‚¢’l‚ھ—ˆٹْ‚إ‚àڈo‚ؤ‚‚é‰آ”\گ«‚ھچ‚‚¢‚©‚ç‚إ‚·پB
پ@•د“®‚حٹة‚â‚©‚إ‚·‚ھپA‚¸‚ء‚ئƒTƒCƒRƒچ‚إگ³‚ج–ع‚ھڈo‘±‚¯‚é‚ئپA‚±‚جŒn—ٌ‚حچغŒہ‚ب‚‘‰ء‚µ‚ؤ‚¢‚‚و‚¤‚ةپAڈمŒہپE‰؛Œہ‚ح‚ ‚è‚ـ‚¹‚ٌپB
پ@—ˆٹْ‚ج’l‚ح‘Oٹْ‚ج’l‚ةژ—‚ؤ‚é‚ئ‚¢‚¤‚ج‚ً•\‚·‚ج‚ةپAƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚ح•ض—ک‚ب‚ٌ‚إ‚·‚ثپB
‚±‚ê‚إ‚و‚¤‚â‚پA–{‘è‚جƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚جگà–¾‚ةˆع‚ê‚ـ‚·پB
پ@‚±‚¢‚آ‚ھ‰½‚ب‚ج‚©‚ئ‚¢‚¤‚ئپAŒ©‚¦‚ب‚¢ڈَ‘ش‚ج•”•ھ‚ھƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚µ‚ؤ‚¢‚é‚ئ‚ف‚ب‚µ‚ؤ‚¢‚郂ƒfƒ‹‚ج‚±‚ئ‚إ‚·پBڈَ‘ش‚ھƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚µ‚ؤ‚¢‚ؤپA‚»
‚ê‚ةٹد‘ھŒëچ·‚إ‚ ‚é‚ئ‚±‚ë‚جƒmƒCƒY‚ھ‰ء‚ي‚ء‚ؤگ¶‚¶‚½‚ج‚ھٹد‘ھ’l‚¾پA‚ئ‚ف‚ب‚µ‚ؤ‚¢‚ـ‚·پB‚¾‚©‚ç•ت–¼‚ھƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒNپ@ƒvƒ‰ƒXپ@ƒmƒCƒYƒ‚ƒfƒ‹‚ب‚ٌ‚إ‚·‚ثپB
پ@‘O‚جƒyپ[ƒW‚جŒvژZ—ل‚إ‚ح“ٌ‚آ‚ج•ھژU‚ًچإ–ق–@‚ًژg‚ء‚ؤگ„’肵‚ـ
‚µ‚½پBˆê‚آ‚حٹد‘ھŒëچ·‚ج‘ه‚«‚³پB‚à‚¤ˆê‚آ‚حڈَ‘ش‚»‚ج‚à‚ج‚ھ•د“®‚·‚é‚»‚ج‘ه‚«‚³‚إ‚·پB
پ@گ³‹K•ھ•z‚¾‚ج•ھژU‚¾‚جŒ¾‚ء‚ؤ‚à‚ي‚©‚è‚ة‚‚¢‚©‚à‚µ‚ê‚ب‚¢‚ج‚إپA‚ـ‚½ƒTƒCƒRƒچ‚ج—ل‚ً‹“‚°‚ـ‚·پB
پ@•ھژU‚ح‚³‚¢‚±‚ë‚ج—ل‚ة‚¨‚¢‚ؤپA‚³‚¢‚±‚ë‚ج–ع‚ھ‚ئ‚肤‚é”حˆح‚¾‚ئژv‚ء‚ؤ‚‚¾‚³‚¢پB‚³‚¢‚±‚낾‚ئ پ|‚Uپ`‚U
‚ج”حˆح‚µ‚©‚ئ‚è‚ـ‚¹‚ٌ‚إ‚µ‚½پB‚¾‚©‚çپAˆêٹْ‘O‚و‚èپAپ}‚U‚و‚è‘ه‚«‚•د“®‚·‚邱‚ئ‚ح‚ب‚¢‚ئ‰¼’肵‚ؤ‚¢‚½‚ي‚¯‚إ‚·پB‚±‚ê‚ھپAپ}‚P‚O‚ـ‚إ•د“®‚·‚é‚ج‚©پAپ}‚P‚µ‚©
•د“®‚µ‚ب‚¢‚ج‚©‚ًچإ–ق–@ژg‚ء‚ؤ’²‚ׂ½‚ئ‚¢‚¤‚±‚ئ‚إ‚·پBپ@‚ـ‚½پA‚±‚جƒTƒCƒRƒچ‚ة‚حگ³•‰
‚ة•خ‚è‚ھ‚ب‚پAƒTƒCƒRƒچ‚ً‚½‚‚³‚ٌ“ٹ‚°‚½‚ئ‚«‚ج•½‹د’l‚ح‚O‚ة‚ب‚è‚ـ‚·پBپ¦
پ@‚à‚¤ˆê“xپA’P‚ب‚éƒmƒCƒY‚ئƒ‰ƒ“ƒ_ƒ€ƒEƒHپ[ƒN‚جˆل‚¢‚ً–¾ٹm‚ة‚·‚邽‚ك‚ةپA—ل‚ً‹“‚°‚ؤگà–¾‚µ‚ـ‚·پB
پ@چإ–ق–@‚ً‚µ‚½Œ‹‰تپAٹد‘ھŒëچ·‚حپ}‚V‚ج”حˆح‚ًژ‚آ‚±‚ئ‚ھ‚ي‚©‚èپAڈَ‘ش‚ج•د“®‚ج‘ه‚«‚³‚حپ}‚S‚إ‚ ‚邱‚ئ‚ھگ„’è‚إ‚«‚½‚ئ‚µ‚ـ‚·پB
پ@‚Q‚O‚O‚O”N‚جڈَ‘ش‚ح‚P‚O‚إ‚µ‚½پB
پ@‚Q‚O‚O‚P”N‚حپA‚P‚O‚©‚çپ}‚S‚ج”حˆح“à‚إ“®‚‰آ”\گ«‚ھ‚ ‚è‚ـ‚·پBپ@ƒTƒCƒRƒچ‚ًگU‚ء‚½‚çپ{‚R‚ة‚ب‚ء‚½‚ئ‚µ‚ـ‚·پB‚·‚é‚ئپA‚Q‚O‚O‚P”N‚جڈَ‘ش‚ح‚P‚R‚إ‚·پB
پ@ƒmƒCƒY‚ج‘ه‚«‚³‚حڈي‚ةپ}‚V‚ب‚ج‚إپA‚Q‚O‚O‚P”N‚جٹد‘ھ’l‚حپA‚Uپ`‚Q‚O‚ج”حˆح“à‚ةژû‚ـ‚邾‚낤‚ئچl‚¦‚ç‚ê‚ـ‚·پB
پ@‚آ‚¬‚ح‚Q‚O‚O‚Q”N‚إ‚·پB‚Q‚O‚O‚P”N‚جڈَ‘ش‚ھ‚P‚R‚إپAڈَ‘ش‚حپ}‚S‚ج”حˆح“à‚إ“®‚«‚ـ‚·پB‚³‚¢‚±‚ë‚ً“ٹ‚°‚½‚çپ{‚P‚ھڈo‚ـ‚µ‚½پB‚و‚ء‚ؤ‚Q‚O‚O‚Q”N‚جڈَ‘ش‚ح‚P‚S‚إ
‚·پB
پ@ƒmƒCƒY‚ھ‰ء‚ي‚ء‚½ٹد‘ھ’l‚حپA‚Vپ`‚Q‚P‚ج”حˆح“à‚ة‚ب‚邾‚낤‚ئگ„‘ھ‚إ‚«‚ـ‚·پB
پEپEپEپEپEپE‚ئ‚±‚¤‚¢‚¤—¬‚ê‚إ‚·پB
پ@ƒTƒCƒRƒچ‚ً“ٹ‚°‚ؤڈَ‘ش‚ھŒˆ‚ـ‚é‚ئڈ‘‚«‚ـ‚µ‚½‚ھپA‚»‚جƒTƒCƒRƒچ‚حƒ‰ƒ“ƒ_ƒ€‚ة’l‚ًڈo‚µ‚ـ‚·پB‚¶‚ل‚ پAˆêٹْگو‚جڈَ‘ش‚ح‚ا‚¤—\‘ھ‚·‚é‚ج‚ھگ³‰ً‚©‚ئ‚¢‚¤‚ئپA ‚»‚ê‚ح‘Oٹْ‚ج’l‚ئ‘S‚“¯‚¶’l‚ً—\‘ھ’l‚ئ‚µ‚ؤڈo‚·‚±‚ئ‚إ‚·پBƒTƒCƒRƒچ‚ج–ع‚ھگ³‚ة‚ب‚é‚ج‚©•‰‚ة‚ب‚é‚ج‚©‚ي‚©‚炸پA‚»‚ج•½‹د’l‚ح‚O‚ة‚ب‚é‚ء‚ؤ‚¢‚¤‚ٌ‚¾‚ء ‚½‚çپA‘Oٹْ‚ج’l‚ة‚O‚ً‘«‚·‚ج‚ھچإ“K‚ب—\‘ھ‚ة‚ب‚é‚ج‚ح“–‘R‚إ‚µ‚ه‚¤پB‚و‚¤‚·‚é‚ةپA‚±‚جƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚¾‚¯‚إ‚حپAڈ«—ˆ—\‘ھ‚ة‚ح‰½‚ج–ً‚ة‚à—§‚؟‚ـ‚¹‚ٌپB
پ@‚و‚ء‚ؤپAگو‚ظ‚ا‚ج—ل‚ًگ³‚µ‚ڈ‘‚«’¼‚·‚ئژں‚ج‚و‚¤‚ة‚ب‚è‚ـ‚·پB
‚Q‚O‚O‚O”N‚جڈَ‘ش‚ح‚P‚O‚إ‚µ‚½پB
پ@‚Q‚O‚O‚P”N‚حپA‚P‚O‚©‚çپ}‚S‚ج”حˆح“à‚إ“®‚‰آ”\گ«‚ھ‚ ‚è‚ـ‚·پBپ@‚إ‚àپAƒTƒCƒRƒچ‚ج–ع‚ھ‚ا‚ٌ‚ب’l‚ة‚ب‚é‚ج‚©‘S‚‚ي‚©‚è‚ـ‚¹‚ٌپB‚و‚ء‚ؤ‚Q‚O‚O‚P”N‚جڈَ‘ش‚حپA
‘O”N‚ئ“¯‚¶‚P‚O‚ئ—\‘ھ‚³‚ê‚ـ‚µ‚½
پ@ƒmƒCƒY‚ج‘ه‚«‚³‚حڈي‚ةپ}‚V‚ب‚ج‚إپA‚Q‚O‚O‚P”N‚جٹد‘ھ’l‚حپA‚Rپ`‚P‚V‚ج”حˆح“à‚ةژû‚ـ‚邾‚낤‚ئچl‚¦‚ç‚ê‚ـ‚·پEپEپEپEپEپEپB
پ@‚à‚؟‚ë‚ٌƒJƒ‹ƒ}ƒ“ƒtƒBƒ‹ƒ^پ[‚ًژg‚ء‚ؤƒ‚ƒfƒ‹‚ًگ„’肵‚ؤ‚¢‚éˆبڈمپAٹد‘ھƒfپ[ƒ^‚ج’l‚ً‰ء–،‚µ‚ؤڈَ‘ش‚ً•âگ³‚µ‚ؤ‚¢‚ـ‚·پB
پ@‚½‚ئ‚¦‚خپA‚Q‚O‚O‚P”N‚جڈَ‘ش‚ح‚P‚O‚ئ—\‘ھ‚³‚ê‚ؤ‚¢‚ـ‚µ‚½پB‚»‚جŒمٹد‘ھ’l‚ھ“¾‚ç‚ê‚ؤپA‚»‚ج’l‚ھ‚P‚X‚¾‚ء‚½‚ئ‚µ‚ـ‚·پB‚±‚ê‚حپA‚Q‚O‚O‚P”N‚جڈَ‘ش‚ً‰كڈ¬•]‰؟‚µ
‚ؤ‚¢‚½‰آ”\گ«‘ه‚إ‚·پB‚»‚±‚إ—\‘ھ‚³‚ê‚ؤ‚¢‚½ڈَ‘ش‚P‚O‚ً•âگ³‚µ‚ؤ‚P‚R‚¾‚ئ‚¢‚¤Œ‹‰ت‚ئ‚ب‚è‚ـ‚µ‚½پB
پ@ƒmƒCƒY‚ج‘ه‚«‚³‚حڈي‚ةپ}‚V‚ب‚ج‚إپA‚Q‚O‚O‚P”N‚جٹد‘ھ’l‚حپA‚Uپ`‚Q‚O‚ج”حˆح“à‚ةژû‚ـ‚邾‚낤‚ئچl‚¦‚ç‚ê‚ـ‚·پEپEپEپEپEپEپB‚ئ‚¢‚¤‚ج‚ً‰½‰ٌ‚àŒJ‚è•ش‚µپB
پ@ڈ«—ˆ—\‘ھ‚ة‚ح–ً‚ة—§‚؟‚ـ‚¹‚ٌ‚ھپAƒfپ[ƒ^‚³‚¦“¾‚ç‚ê‚ê‚خپA‚»‚جژ‚جڈَ‘ش‚ًگ„’è‚·‚邱‚ئ‚ھ‚إ‚«‚é‚ي‚¯‚إ‚·پB
پ@‚à‚؟‚ë‚ٌپAƒXƒ€پ[ƒWƒ“ƒO‚ً‚·‚é‚ئپA‚à‚ء‚ئڈ«—ˆ‚جٹد‘ھ’l‚àژg‚ء‚ؤڈَ‘ش‚ً•âگ³‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB
پ@ƒچپ[ƒJƒ‹ƒŒƒxƒ‹ƒ‚ƒfƒ‹‚»‚ج‚à‚ج‚ح—\‘ھ‚ة–ً—§‚؟‚ـ‚¹‚ٌ‚ھپA‚±‚ê‚ً”“W‚³‚¹‚éٹ´‚¶‚إƒ‚ƒfƒ‹‚ً•،ژG‚ة‚µ‚ؤ‚¢‚¯‚خپAڈ‚µ‚ح‚ـ‚ئ‚à‚ب—\‘ھ‚ًڈo‚·‚±‚ئ‚ھ‚إ‚«‚ـ
‚·
پ¦
پ@“®“IگüŒ`ƒ‚ƒfƒ‹‚إ‚حپAٹد‘ھŒëچ·‚àپAڈَ‘ش‚ج•د“®‚àپAگ³‹K•ھ•z‚ةڈ]‚¤‚ئ‰¼’肳‚ê‚ؤ‚¢‚ـ‚·پBگ³‹K•ھ•z‚ء‚ؤ
‚ج‚حپA‚QپD‚Q‚S‚ئ‚©ڈ¬گ”“_ˆب‰؛‚ج’l‚à•½‹C‚إ‚ئ‚è‚ـ‚·‚µپAƒTƒCƒRƒچ‚ف‚½‚¢‚ةپuگâ‘خ‚S‚و‚è‘ه‚«‚بگ”‚حڈo‚ب‚¢پv‚ب‚ٌ‚ؤگ§–ٌ‚à‚ ‚è‚ـ‚¹‚ٌپB‚±‚±‚ح‚؟‚ه‚ء‚ئ‹C‚ً•t‚¯
‚ؤ‚‚¾‚³‚¢پB”O‚ج‚½‚كپB
پ@ژں‚حپAڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ج“ïڈٹ‚ئ‚¢‚¤‚©پAƒpƒb‚ئŒ©‚و‚‚ي‚©‚ٌ‚ب‚¢پuچ¶’[پv‚ة‚آ‚¢‚ؤگà–¾‚µ‚ـ‚·پB‚à‚؟‚ë‚ٌچ¶’[‚ئ‚¢‚¤‚ج‚حژ„‚ج‘¢Œê‚إ‚·‚ھپB‚ظ‚©‚جŒ¾‚¢•û
‚ھ“‚¢پA•¶ژڑ’ت‚èپu‚ذ‚¾‚è‚ح‚µپv‚ج–â‘è‚إ‚·پB
پ@چ،‚ـ‚إ‚ج—ل‚إ‚ح‚³‚è‚°‚ب‚پAپu‚Q‚O‚O‚O”N‚جڈَ‘ش‚ح‚P‚O‚إ‚µ‚½پv‚©‚çکb‚ًگi‚ك‚ؤ‚¢‚ـ‚µ‚½‚ھپA‚±‚ج‚Q‚O‚O‚O”N‚جڈَ‘ش‚ء‚ؤپA‚ا‚¤ˆµ‚¦‚خ‚و‚¢‚ج‚إ‚µ‚ه‚¤ ‚©پBƒOƒ‰ƒt‚ة‚·‚é‚ئˆê”شچ¶’[‚ج•”•ھ‚ب‚ج‚إپAژ„‚حڈںژè‚ةچ¶’[‚ئŒؤ‚ٌ‚إ‚ـ‚·پB‚ظ‚©‚جگl‚ةگà–¾‚·‚é‚ئ‚«‚ةچ¶’[‚ء‚ؤŒ¾‚ء‚ؤ‚à’ت‚¶‚ب‚¢‚ج‚إ‹C‚ً•t‚¯‚ؤ‚‚¾‚³‚¢پBپB
پ@‚±‚جچ¶’[‚ج’lپA‚„‚Œ‚چƒpƒbƒPپ[ƒW‚إ‚حƒfƒtƒHƒ‹ƒg‚إ‚O‚ئ‚ب‚ء‚ؤ‚¢‚ـ‚·پBNileƒfپ[ƒ^‚¾‚ئگç‚¢‚‚آ‚ئ‚©‚¢‚¤’Pˆت‚¾‚ء‚½‚ٌ‚إ‚·‚ھپA‚»‚ê‚إ‚àپAچ¶’[‚ح ‚OپA‚ئژw’肵‚ؤ‚¢‚ـ‚·پB‚±‚جچ¶’[‚ج’l‚ح‘O‚جƒyپ[ƒW‚جŒvژZ—ل‚إƒ‚ƒfƒ‹‚ج پuŒ^پv‚ً•\ژ¦‚³‚¹‚½‚ئ‚«‚ةژہ‚حڈo‚ؤ‚«‚ؤ‚¢‚ؤپA‚à‚¤ˆê“x•\ژ¦‚·‚é‚ئپA
> mod.Nile
$FF
[,1]
[1,] 1
$V
[,1]
[1,] 15099.75
$GG
[,1]
[1,] 1
$W
[,1]
[1,] 1468.459
$m0
[1] 0
$C0
[,1]
[1,] 1e+07
‚±‚جپA‘¾ژڑ‚إژ¦‚µ‚½m0‚ج‚ئ‚±‚ë‚إ‚·پB‚O‚ة‚ب‚ء‚ؤ‚ـ‚·‚و‚ثپB
پ@‘O‰ٌپAگ„’肳‚ꂽڈَ‘ش‚ًƒOƒ‰ƒt‚ة•\ژ¦‚³‚¹‚é‚ئ‚«پ@dropFirstپ@‚ئ‚¢‚¤ٹضگ”‚ًژg‚ء‚ؤپAچ¶’[‚ج’l‚ًژو‚èڈœ‚¢‚ؤ‚©‚çƒvƒچƒbƒg‚µ‚ؤ‚¢‚ـ‚µ‚½پB‚±‚ج——R
‚حپAچ¶’[‚ھ‚O‚¾‚©‚ç‚إ‚·پBگ„’肵‚ؤ‚¢‚ب‚¢‚ٌ‚¾‚©‚çپA•\ژ¦‚³‚¹‚é‚ئپA‚¤‚ء‚ئ‚¤‚µ‚¢‚±‚ئ‚ة‚ب‚é‚ج‚إپAگط‚ء‚½‚ٌ‚إ‚·‚ثپB‚؟‚ب‚ف‚ةچإŒم‚جC0‚حپAچ¶’[‚ة‚¨‚¯‚é•ھژU
‚ج’l‚إ‚·پB‚±‚ê‚àڈںژè‚ب’l‚ھ‰¼’肳‚ê‚ؤ‚¢‚ـ‚·پB
پ@‘Oƒyپ[ƒW‚ج—ل‚ًŒ©‚ê‚خ‚ي‚©‚é‚و‚¤‚ةپA‚ׂآ‚ةپA‚±‚ج‚ـ‚ـ‚إ‚àƒ‚ƒfƒ‹‚حگ„’è‚إ‚«‚ـ‚·پB‚ب‚؛‚©‚ئ‚¢‚¤‚ئپAƒJƒ‹ƒ}ƒ“ƒtƒBƒ‹ƒ^پ[‚إ‚حٹد‘ھƒfپ[ƒ^‚ًژg‚ء‚½•âگ³
‚ھچs‚ي‚ê‚ؤ‚¢‚é‚©‚ç‚إ‚·‚ثپB
پ@Nileƒfپ[ƒ^‚ح‚P‚X‚V‚P”N‚©‚瑶چف‚µ‚ـ‚·پB‚P‚X‚V‚P”N‚جڈَ‘ش‚ًگ„’è‚·‚邽‚ك‚ة‚حچ¶’[‚ئ‚µ‚ؤ‚P‚X‚V‚O”N‚جڈَ‘ش‚ج’l‚ھ•K—v‚إ‚·پB‚»‚ê‚ً‚O‚¾‚ئ‰¼’肵‚½پB
‚إپA‚P‚X‚V‚P”N‚جڈَ‘ش‚حپA‘Oٹْ‚جڈَ‘ش‚ج’l‚ئ‘S‚“¯‚¶‚¾‚ئ‚ف‚ب‚³‚ê‚é‚ج‚إ‚O‚¾‚ئ—\‘ھ‚³‚ê‚éپB‚P‚X‚V‚P”N‚جژہچغ‚ج—¬—ت‚ح‚P‚P‚Q‚O‚إ‚µ‚½‚ج‚إپA‚O‚ئ‚¢‚¤‚ج‚ح–ز—َ
‚ب‰كڈ¬•]‰؟‚¾پA‚ئ‚¢‚¤‚±‚ئ‚إ‚·‚²‚¢گ¨‚¢‚إ•âگ³‚³‚ꂽ‚ٌ‚إ‚·‚ثپB
پ@‘O‰ٌ‚ج—ل‚¾‚ئNileFilt$m‚ً‚·‚ê‚خپAگ„’肳‚ꂽڈَ‘ش‚ھ•\ژ¦‚إ‚«‚é‚ئڈ‘‚«‚ـ‚µ‚½‚ھپA‚±‚ج’l‚ح‚P‚X‚V‚O”N‚©‚ç‚جƒXƒ^پ[ƒg‚ئ‚ب‚ء‚ؤ‚¢‚ـ‚·پBNile
ƒfپ[ƒ^‚ح‚P‚X‚V‚P”N‚©‚çƒXƒ^پ[ƒg‚ب‚ج‚ة“ن‚ة‚P‚X‚V‚O”N‚ھ‘¶چف‚µ‚ؤپA‚»‚±‚ة‚O‚ھ“ü‚ء‚ؤ‚¢‚é‚ئ‚¢‚¤‚ج‚حپA‚±‚ê‚ھŒ´ˆِ‚إ‚·پB‚±‚ê‚ًdropFirstژg‚ء‚ؤ”rڈœ
‚µ‚½‚ئپB
پ@‚إپA•âگ³‚³‚ꂽڈَ‘ش‚ًژg‚ء‚ؤ‚P‚W‚V‚Q”Nˆبچ~‚ھگ„’肳‚ê‚ؤ‚¢‚é‚©‚çپAˆê‰–â‘è‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚إ‚·پB‚„‚Œ‚چ‚جƒ}ƒjƒ…ƒAƒ‹Œ©‚ؤ‚é‚ئپAŒ‹چ\چ¶’[‚ح‚O‚ج‚ـ‚ـگ„’肵
‚ؤ‚¢‚é‚ئ‚«‚ھ‘½‚¢‚و‚¤‚ب‹C‚ھ‚µ‚ـ‚·پB
پ@چ¶’[‚ةٹض‚µ‚ؤ‚ح‚ظ‚©‚ة‚à‚¢‚‚آ‚©‘خچô‚ھ‚ ‚è‚ـ‚·پB
پ@ˆê‚آ‚حپAچ¶’[‚ًپAƒfپ[ƒ^‚à‚ë‚ئ‚àگط‚ء‚ؤژج‚ؤ‚邱‚ئپBNile‚جƒfپ[ƒ^‚ح‚P‚W‚V‚Q”N‚©‚炵‚©‚ب‚¢‚ئ‚ف‚ب‚·‚ٌ‚إ‚·‚ثپB‚إپAگV‚µ‚گو’[‚جƒfپ[ƒ^‚ئ‚ب‚ء‚½
‚P‚W‚V‚Q”N‚ة‚¨
‚¯‚éچ¶’[‚ةپA‚P‚W‚V‚P”N‚جٹد‘ھ’l‚ً“ü‚ê‚é‚ٌ‚إ‚·پB‚±‚¤‚â‚ê‚خپiٹد‘ھŒëچ·‚ھ“ü‚ء‚ؤ‚¢‚é‚ج‚إ‚P‚W‚V‚P”N‚جڈَ‘ش‚»‚ج‚à‚ج‚إ‚ح‚ب‚¢‚إ‚·‚ھپj‚ ‚é’ِ“xگ³‚µ‚»‚¤‚بچ¶’[
‚ً‰¼’肵‚ؤƒ‚ƒfƒ‹‚ً‘g‚ق‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB‚½‚¾‚µپA‚±‚ج‚â‚è•û‚¾‚ئپAژg‚¦‚éƒfپ[ƒ^‚ھˆêٹْ•ھڈ‚ب‚‚ب‚ء‚ؤ‚µ‚ـ‚¢‚ـ‚·پB‚ ‚ٌ‚ـ‚è•·‚¢‚½‚±‚ئ‚ب‚¢‚â‚è•û‚إ‚·‚ھپA
پi‚؟‚ه‚ء‚ئ
ˆل‚¤‰ًگح‚إ‚·‚ھپjƒŒƒtƒFƒٹپ[‚ة‚±‚¤‚µ‚½‚çپA‚ئٹ©‚ك‚ç‚ꂽ‚±‚ئ‚ھ‚ ‚è‚ـ‚·پB
پ@“ٌ”ش–ع‚حچ¶’[‚ئ‚¢‚¤ƒpƒ‰ƒپƒ^‚àچإ–ق–@‚إگ„’肵‚ؤ‚µ‚ـ‚¤•û–@‚إ‚·پBگ„’è‚·‚ׂ«ƒpƒ‰ƒپƒ^‚ھ‘‚¦‚ؤ‚µ‚ـ‚¢پA‚â‚â‘ه•د
‚ئ‚¢‚¤Œ‡“_‚ح‚ ‚è‚ـ‚·‚ھپAژèژ‚؟‚جƒfپ[ƒ^‚ً‘S•”ژg‚ء‚ؤƒ‚ƒfƒ‹‚ً‘g‚ك‚ـ‚·پB
پ@ژO”ش–ع‚حپAˆج‚¢گوگ¶‚ھŒˆ‚ك‚½‚ئ‚©—ک_“I‚بچlژ@‚ةٹî‚أ‚¢‚ؤ‚ب‚؛‚©‚à‚¤‚·‚إ‚ة‚ي‚©‚ء‚ؤ‚é‚ئ‚©‚¢‚¤ڈêچ‡‚إ‚·پB‚±‚ê‚حپA‚ي‚©‚ء‚ؤ‚é’l‚ً‚»‚ج‚ـ‚ـژg‚¦‚خ‚¢‚¢
‚إ‚·پBگ…ژY‚جڈêچ‡‚حگ_—l‚ةگu‚‚µ‚©‚ب‚¢‚و‚¤‚بپH
ژہچغ‚ةƒچپ[ƒJƒ‹پEƒŒƒxƒ‹پEƒ‚ƒfƒ‹‚ًگ„’肵‚ؤ‚ف‚ـ‚·پB
‘O‚جƒyپ[ƒW‚إٹب’P‚بƒ‚ƒfƒ‹‚حˆê‰گ„’è‚حڈI‚ي‚ء‚ؤ‚¢‚é‚ج‚إپAچ¶’[‚àˆêڈڈ‚ةگ„’肵‚ؤ‚ف‚ـ‚·پB
ƒXƒNƒٹƒvƒg‚ح‚ـ‚ئ‚ك‚ؤ‚±
‚؟‚ç‚ة‚¨‚¢‚ؤ‚ ‚è‚ـ‚·پB
‚ـ‚¸‚ح‚„‚Œ‚چƒpƒbƒPپ[ƒW‚ً—ژ‚ئ‚µ‚ؤ‚©‚çپB
> library(dlm)
‚ئ‚µ‚ؤ‚©‚çپAŒvژZ‚µ‚ؤ‚¢‚«‚ـ‚·پB
Step1پ@Œ^‚جچىگ¬
build.2<-function(theta){
dlmModPoly(order=1,dV=exp(theta[1]),dW=exp(theta[2]),m0=exp(theta[3]))
}
گ„’è‚·‚ׂ«ƒpƒ‰ƒپƒ^‚ھ‚¢‚ء‚±‚س‚¦‚½‚ج‚إپA,m0=exp(theta[3])‚ھ
“ü‚ء‚ؤ‚ـ‚·پBژc‚è‚ح‘O‚ئˆêڈڈ‚إdV‚حٹد‘ھŒëچ·‚ج‘ه‚«‚³پAdW‚حڈَ‘ش‚ج•د“®‚ج‘ه‚«‚³‚إ‚·پB
Step2پ@ƒpƒ‰ƒپƒ^گ„’è
fit.2<-dlmMLE(Nile,parm=dlmMLE(Nile,parm=c(1,1,10),build.2,method="Nelder-Mead")$par,
پ@build.2,method="BFGS")
پ@‚±‚±‚إپA‚؟‚ه‚ء‚ئ‚¾‚¯چH•v‚ً‚µ‚ـ‚µ‚½پB‚ئ‚¢‚¤‚ج‚àپAگ„’è‚·‚ׂ«ƒpƒ‰ƒپƒ^‚ھˆêŒآ‘‚¦‚½‚ج‚إپAگ„’è‚ھ‚؟‚ه‚ء‚ئ‘ه•د‚ة‚ب‚ء‚ؤ‚¢‚é‚ٌ‚إ‚·‚ثپB‚¾‚©‚çپA‚س‚آ‚¤‚ةگ„
’è‚·‚é‚ئپA•د‚بگ„’è’l‚ھڈo‚ؤ‚µ‚ـ‚¤‚±‚ئ‚ھ‚ ‚è‚ـ‚·پB
پ@dlmMLE‚ئ‚¢‚¤ٹضگ”‚حoptimٹضگ”‚ئ‚¢‚¤چإ“K‰»ٹضگ”‚ً‚»‚ج‚ـ‚ـژg‚ء‚ؤ‚¢‚ـ‚·پB‚ب‚ج‚إپAoptimٹضگ”‚إژg‚¦‚éڈ ‚ج‹Z‚ھ‚±‚؟‚ç‚إ‚àژg‚¦‚é‚ٌ‚إ‚·‚ثپB
optimٹضگ”‚ًژg‚¤ژ‚جچH•v‚ج•û–@‚حپA•¶Œ£[1]‚ةچع‚ء‚ؤ‚¢‚ـ‚·پB‚±‚جٹضگ”‚حŒ‹چ\گ„’è‚ً‚و‚ƒ~ƒX‚é‚ج‚إپAڈ‚µ‚إ‚à‚ـ‚µ‚بگ„’è’l‚ًڈo‚»‚¤‚ئ‚¢‚¤گوگl‚ج’mŒb
‚ھ‚½‚‚³‚ٌچع‚ء‚ؤ‚ـ‚·پB
پ@چ،‰ٌ‚ح‘½’iٹKچإ“K‰»‚ئ‚¢‚¤‹Z‚ًژg‚ء‚ؤ‚ف‚ـ‚µ‚½پB‚ـ‚¸‚حپAdlmMLE‚ًژg‚ء‚ؤ•پ’ت‚ةƒpƒ‰ƒپƒ^‚ً‹پ‚ك‚½ŒمپA‚»‚جگ„’肳‚ꂽƒpƒ‰ƒپƒ^‚ًڈ‰ٹْ’l‚ة‚µ‚ؤ‚à‚¤ˆê“x
چإ“K‰»‚µ‚ؤ‚â‚é•û–@‚إ‚·پB‚±‚¤‚·‚ê‚خپAˆê”شچإڈ‰‚ة“K“–‚ة“ث‚ءچ‚ٌ‚¾ڈ‰ٹْ’lپiparm=c(1,1,10)‚ج
•”•ھپj‚ج‚¹‚¢‚إگ„’茋‰ت‚ھ‚¨‚©‚µ‚‚ب‚é‚ئ‚¢‚¤ژ–‘ش‚ًٹةکa‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB
پ@‚±‚ج‚â‚è•û‚ج‚¨‚©‚°‚إ‘½ڈ‚ـ‚µ‚ة‚ح‚ب‚ء‚½‚ج‚إ‚·‚ھپA‚»‚ê‚إ‚àˆê”شچإڈ‰‚ة“ü‚ê‚éڈ‰ٹْ’l‚ة‚و‚ء‚غ‚ا•د‚ب’l‚ً“ü‚ê‚é‚ئˆس–،•s–¾‚بگ„’è’l‚ھ•ش‚³‚ê‚ـ‚·پB‹C‚ً•t‚¯
‚ؤ‚‚¾‚³‚¢پB
پ@‚¤‚ـ‚گ„’è‚إ‚«‚ؤ‚¢‚é‚©‚ا‚¤‚©‚حگ„’茋‰ت‚ة‚¨‚¯‚éconvergence‚ًŒ©‚é‚ئ‚و‚¢‚إ‚·پB
> fit.2
$par
[1] 9.622387 7.292300 7.013394
$value
[1] 549.63
$counts
function gradient
13 7
$convergence
[1] 0
$message
NULL
‘¾ژڑ‚ة‚µ‚½•”•ھ‚إ‚·‚ثپB‚±‚ê‚ھ0‚ة‚ب‚ء‚ؤ‚¢‚ê‚خ‚ئ‚è‚ ‚¦‚¸‰ً‚ھ‚؟‚ل‚ٌ‚ئ‹پ‚ـ‚ء‚½‚ئ‚¢‚¤‚±‚ئ‚ة‚ب‚è‚ـ‚·پB
پ@‚إ‚àپA‚±‚±‚ھ0‚إ‚àˆس–،•s–¾‚بگ„’è’l‚ً•ش‚µ‚ؤ‚¢‚邱‚ئ‚ھ‚ ‚è‚ـ‚·پBڈ‰ٹْ’l‚ًڈ‚µ•د‚¦‚ؤ‚ف‚ؤپAگ„’肳‚ꂽƒpƒ‰ƒپƒ^‚ھ‚ا‚ج‚و‚¤‚ة•د‰»‚·‚é‚©Œ©‚ؤ‚¨‚¢‚½‚ظ‚¤‚ھ
‚¢‚¢‚ئژv‚¢‚ـ‚·پB
گ„’肳‚ꂽƒpƒ‰ƒپƒ^‚ًژg‚ء‚ؤƒ‚ƒfƒ‹‚ً‘g‚ف‚ب‚¨‚µ‚ـ‚·
DLM.2<-build.2(fit.2$par)
> DLM.2
$FF
[,1]
[1,] 1
$V
[,1]
[1,] 15099.05
$GG
[,1]
[1,] 1
$W
[,1]
[1,] 1468.945
$m0
[1] 1111.421
$C0
[,1]
[1,] 1e+07
‚چ‚O‚ة‚à‚»‚ê‚ء‚غ‚¢’l‚ھ“ü‚è‚ـ‚µ‚½پB‚»‚ê‚ء‚غ‚¢’l‚©پAپuگâ‘خ‚±‚ê‚ح‚ب‚¢‚¾‚ëپv‚ء‚ؤ’l‚©‚ح‚؟‚ل‚ٌ‚ئٹm”F‚µ‚½‚ظ‚¤‚ھ‚و‚¢‚ئژv‚¢‚ـ‚·پB‚»‚ê‚‚ç‚¢گ„’è’l‚حگM—p‚ب
‚ç‚ب‚¢‚إ‚·پB
‚ ‚ئ‚حپA‘O‰ٌچى‚ء‚½ƒ‚ƒfƒ‹‚ئ“¯‚¶‚ب‚ج‚إپAڈب—ھ‚µ‚ـ‚·پB
پ@چ،“x‚حپAƒ^ƒCƒgƒ‹‚ج’ت‚èپAڈَ‘ش‚ج•ھژU‚ً‚O‚¾‚ئ‰¼’肵‚ؤƒ‚ƒfƒ‹‚ً‘g‚ٌ‚إ‚ف‚ـ‚·پB
پ@‚±‚ê‚ح‚¢‚ء‚½‚¢‰½‚ب‚ج‚©‚ئ‚¢‚¤‚ئپAٹد‘ھ’n‚ج•د“®‚ح100%ٹد‘ھŒëچ·‚ة‚و‚é‚à‚ج‚إ‚ ‚èپAŒ©‚¦‚ب‚¢پuڈَ‘شپv‚ج•”•ھ‚ح‘S‚•د“®‚µ‚ؤ‚¢‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚ً‰¼’肵‚ؤ
‚¢‚é‚ي‚¯‚إ‚·پB
#پ@Step1
#پ@ƒ‚ƒfƒ‹چىگ¬‚ج‚½‚ك‚جٹضگ”‚ًچى‚é
build.3<-function(theta){
dlmModPoly(order=1,dV=exp(theta[1]),dW=0,m0=exp(theta[2]))
}
#پ@Step2
#پ@MLE‚إƒpƒ‰ƒپƒ^گ„’èپB
fit.3<-dlmMLE(Nile,parm=dlmMLE(Nile,parm=c(1,7),build.3,method="Nelder-Mead")$par,build.3,method="BFGS")
# گ„’肳‚ꂽƒpƒ‰ƒپƒ^‚ًژg‚ء‚ؤƒ‚ƒfƒ‹‚ًچى‚è’¼‚·
DLM.3<-build.3(fit.3$par)
# Step3
# ƒJƒ‹ƒ}ƒ“ƒtƒBƒ‹ƒ^پ[
Nile.Filt.3<-dlmFilter(Nile,DLM.3)
# Step4
# ƒXƒ€پ[ƒWƒ“ƒO
Nile.Smooth.3<-dlmSmooth(Nile.Filt.3)
# plot
plot(Nile,col=8,type="o",main="ƒXƒ€پ[ƒWƒ“ƒO‚جŒ‹‰ت")
lines(Nile.Smooth.3$s,col=4)
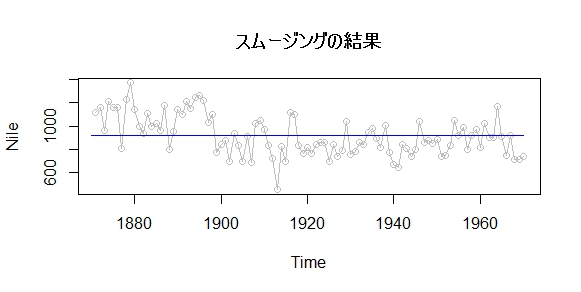
چ،‰ٌ‚حƒXƒ€پ[ƒWƒ“ƒO‚جŒ‹‰ت‚¾‚¯‚ًچع‚¹‚ؤ‚¢‚ـ‚·‚ھپA‚ـ‚ء‚·‚®‚ة‚ب‚ء‚ؤ‚¢‚é‚ج‚ھ‚ي‚©‚é‚ئژv‚¢‚ـ‚·پB
ڈَ‘ش‚ھ‘S‚“®‚©‚ب‚¢‚ئ‚¢‚¤‚ج‚حپAژہ‚حپA‚س‚آ‚¤‚جگüŒ`‰ٌ‹A‚ًچs‚ء‚½Œ‹‰ت‚ئˆê’v‚µ‚ـ‚·پB
lm.model<-lm(Nile~1)
پھ‚حپAگà–¾•دگ”‚ج“ü‚ء‚ؤ‚¢‚ب‚¢گüŒ`‰ٌ‹A‚إ‚·پBŒX‚«‚ھ‚O‚ج’¼گü‚ًˆّ‚ء’£‚éڈˆ—‚إ‚·‚ثپBگط•ذ‚¾‚¯‚ًگ„’肵‚½‚ي‚¯‚إ‚·پB
پ@‚±‚ê‚جگط•ذ‚جگ„’茋‰ت‚ح
> lm.model$coef
(Intercept)
919.35
ˆê•ûپA‚„‚Œ‚چژg‚ء‚ؤˆّ‚ء’£‚ç‚ꂽگü‚ح‚±‚ٌ‚ب’l‚ة‚ب‚ء‚ؤ‚ـ‚·پB
> Nile.Smooth.3$s
Time Series:
Start = 1870
End = 1970
Frequency = 1
[1] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[11] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[21] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[31] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[41] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[51] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[61] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[71] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[81] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[91] 919.35 919.35 919.35
919.35 919.35 919.35 919.35 919.35 919.35 919.35
[101] 919.35
—¼•û‚ئ‚à‚X‚P‚XپD‚R‚T‚ة‚ب‚ء‚ؤ‚¢‚ـ‚·‚ثپB‚؟‚ب‚ف‚ة
> mean(Nile)
[1] 919.35
Nile‚ج•½‹د’l‚ح‚X‚P‚XپD‚R‚T‚إ‚·‚©‚çپA‚±‚ê‚ح’P‚ة•½‹د’l‚ً‹پ‚ك‚½‚ج‚ئ“¯‚¶‚±‚ئ‚ة‚ب‚ء‚ؤ‚¢‚é‚ئ‚¢‚¤‚±‚ئ‚إ‚·پB
‚±‚ê‚ً‚·‚ê‚خپAڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ئ‰ٌ‹A•ھگح‚جٹضŒW‚ھ‘½ڈ‚ح‚ي‚©‚é‚©‚ب‚ئژv‚¢‚ـ‚·پB‰ٌ‹A•ھگح‚حپAڈَ‘ش‚ج•ھژU‚ھ‚O‚إ‚ ‚é‚ئ‰¼’肳‚ꂽڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ئ‚ف‚ب
‚¹‚é‚ٌ‚إ‚·‚ثپB‚¾‚©‚çپAڈَ‘ش‹َٹشƒ‚ƒfƒ‹‚ج‚ظ‚¤‚ھƒpƒڈپ[ƒAƒbƒv‚µ‚ؤ‚¢‚é‚ئ‚¢‚¤‚±‚ئ‚إ‚·پB
پ@ƒoƒO‚âŒë‚è“™‚²‚´‚¢‚ـ‚µ‚½‚çپAŒfژ¦”آ‚ب‚ا‚ة‚²ˆê•ٌ‚‚¾‚³‚¢پB
ژQچl•¶Œ£
[1] ”ؤ—pچإ“K‰»ٹضگ”optim()‚جژg—p–@
http://www.okada.jp.org/RWiki/?%B4%D8%BF%F4%A4%CE%BA%C7%C2%E7%A1%A6%BA%C7%BE%AE%B2%BD
[2] J.J.FƒRƒ}ƒ“ƒ_پ[پAS.JƒNپ[ƒvƒ}ƒ“پ@کaچ‡”£ –َپFپ@ڈَ‘ش‹َٹشژŒn—ٌ•ھگح“ü–هپC‚Q‚O‚O‚W
[3] G,Petris, S Petrone, P Campagnoli: Dynamic Linear Models with R, ‚Q‚O‚O‚X
‘O‚جƒyپ[ƒWپ@پثپ@‚„‚Œ‚چ‚جژg‚¢•ûپ@‚ض
ژں‚جƒyپ[ƒWپ@پثپ@‹Gگك‚ئƒgƒŒƒ“ƒhپ@‚ض